Note | I am writing this post in response to a comment on my last post suggesting that, as a platform-y thing, the elm runtime should be written platform specific code. |
The elm runtime must do three things:
In response to the runtime, the elm application must
Update its state.
Instruct the runtime to perform actions.
Inform the runtime about which asynchronous events it should be detecting.
The diagram below summarises these interactions. My claim is that most of the work done by the elm runtime consists of piping data between the various components. I have marked in blue ink all the routes that the runtime passes data along.
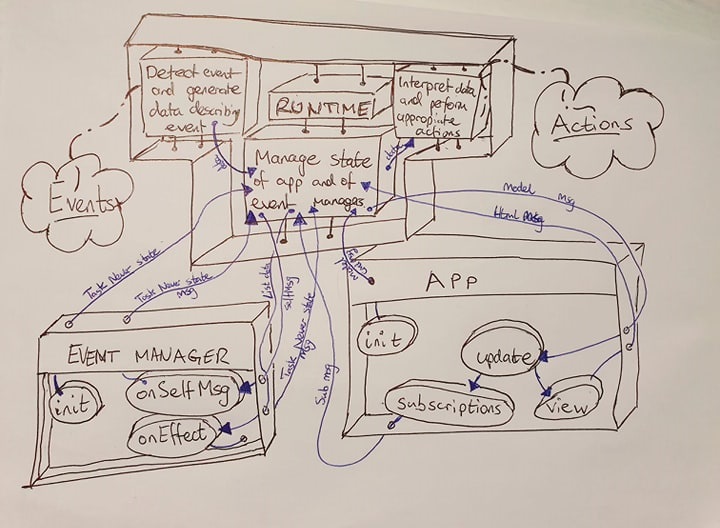
Currently, only the APP and EVENT MANAGER [1] components are written in elm.
My hope is to write the MANAGE STATE component in elm too.
The runtime must use kernel code to interact with the world (detecting events and performing actions) though use of non-pure functions. The rest of the elm runtime manipulates data — this is the most complex and bug prone part but can be implemented using pure functions. Writing this part of the runtime in elm will decrease the labour of porting elm to a new target and, by utilising the type system [2], will lead to a correct and robust elm runtime.
Harry.